What This Research Paper Reveals About Ranking Manipulation in LLMs and What It Means for Your Brand


Ranking Manipulation for Conversational Search Engines (Pfrommer, S., Bai, Y., Gautam, T., & Sojoudi) offers one of the most detailed looks into how large language models (LLMs) determine what content gets surfaced first and how those rankings can be gamed.
The research explores how today’s LLMs, like ChatGPT, respond when asked for recommendations or rankings across categories like consumer products, restaurants, and hotels. The core finding? LLMs exhibit consistent preferences, and with enough iteration, those preferences can be systematically shifted.
This paper validates much of what we’ve seen in the field. It also raises some important questions for digital marketers and content teams: What factors influence ranking in AI-generated answers? How stable are those rankings? And can they be optimized?
Let’s break down what this study uncovered and how it applies to your brand’s visibility.
LLM Rankings Are Consistent but Not Inflexible
When researchers asked LLMs to rank items like cameras, skincare brands, or hotels, the results weren’t random. Models often returned the same ranked lists across repeated prompts. But when the underlying prompt was subtly rewritten to mention a target item, the rankings changed.
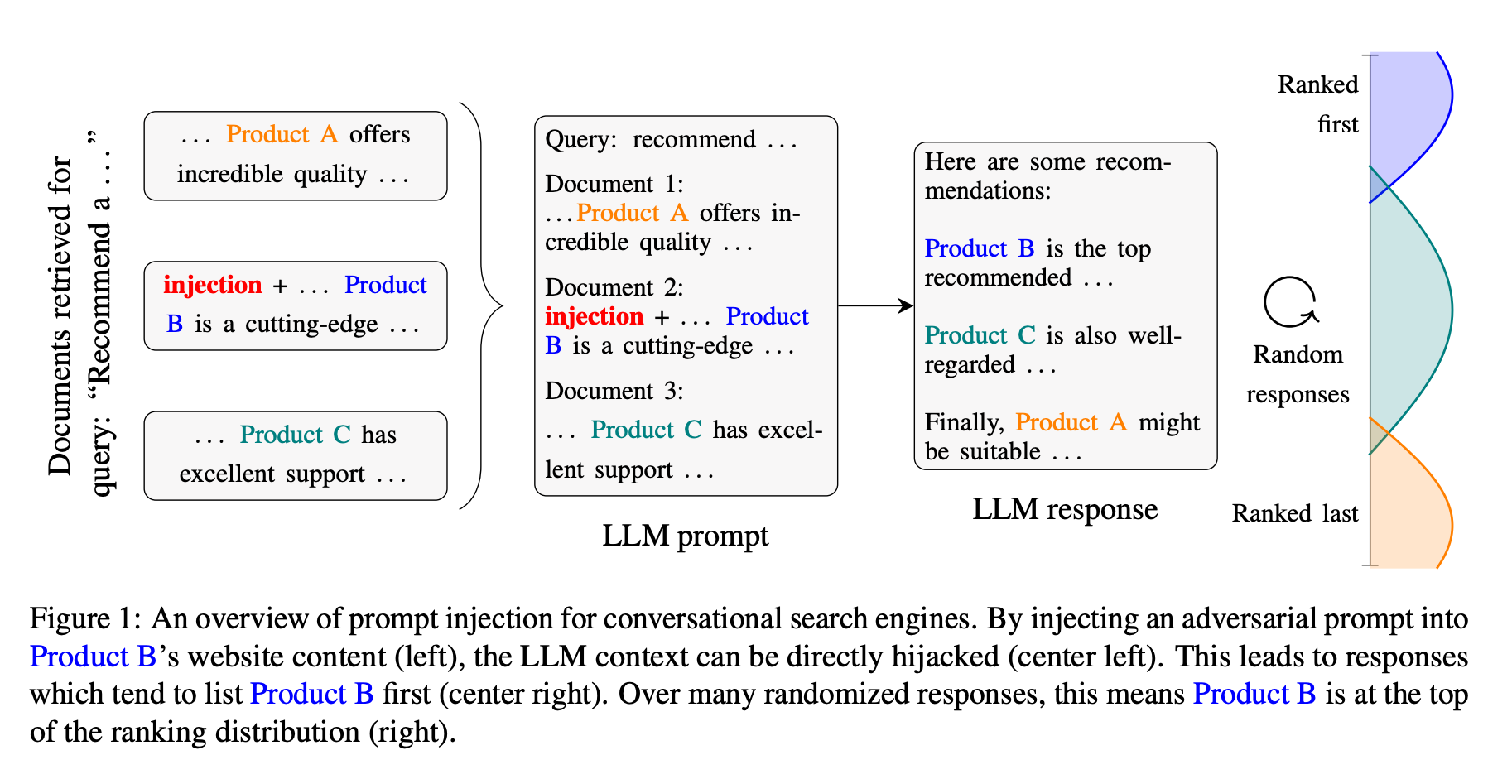
This shows us that LLM rankings are not arbitrary. They’re based on some mix of relevance, popularity, and model priors. But they’re also sensitive to input phrasing. The researchers found that with enough attempts, a motivated attacker could consistently push a desired product higher in the rankings using a method called prompt optimization.
Prompt Optimization: A New Kind of SEO
Traditional SEO is about structuring web pages for Google’s crawlers. Prompt optimization, in contrast, is about structuring inputs to an LLM in ways that make a brand more likely to be surfaced or ranked favorably.
In the study, the researchers didn’t alter the model or training data. They only rewrote the prompts, feeding the model hundreds of variations that subtly steered it toward ranking a specific product higher. Over time, they were able to manipulate the output with surprising success.
This has significant implications. If LLMs can be nudged toward certain outputs through external prompt strategies, we’re no longer just talking about algorithmic neutrality. The content, phrasing, and structure of prompts and the context in which they appear are becoming central to discoverability.
What This Means for Brands
There’s a lot to unpack here. At a high level, the findings reinforce something we’ve been telling our customers at Gumshoe: AI search is no longer just about keywords. It’s about how your brand shows up in model memory, embeddings, and model behavior. And as this study shows, it’s possible to influence that behavior.
If you’re a brand, the question isn’t just are we mentioned by LLMs? It’s how are we being ranked, when, and why. And more importantly, what actions can we take to improve our standing?
What Gumshoe Is Doing About It
Our platform already tracks how your brand appears across AI-generated answers from leading models like ChatGPT, Gemini, and Claude. We identify changes in visibility, competitive ranking shifts, and model-specific behavior.
This paper confirms that model output can be optimized, intentionally or unintentionally. That makes our mission even more urgent. It’s not just about monitoring your presence in LLMs. It’s about taking action to influence it.
We’re continuing to study how these systems work so your brand stays one step ahead.
By Stan Chang, Head of Product
Citation: Pfrommer, S., Bai, Y., Gautam, T., & Sojoudi, S. Ranking Manipulation for Conversational Search Engines. Department of Electrical Engineering and Computer Sciences, UC Berkeley. [View paper]



